AI Operations & Orchestration
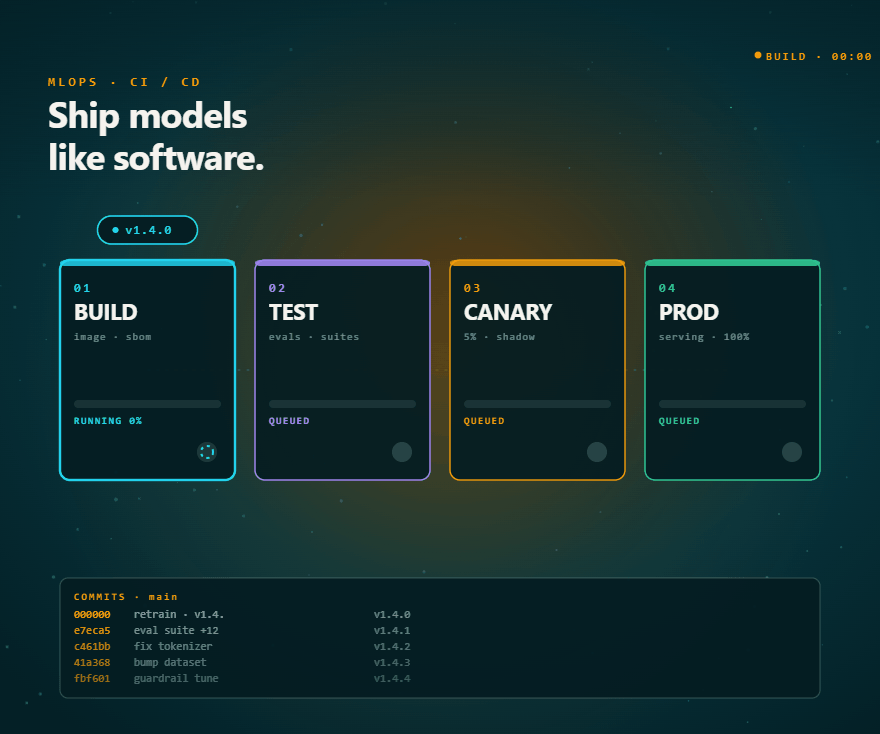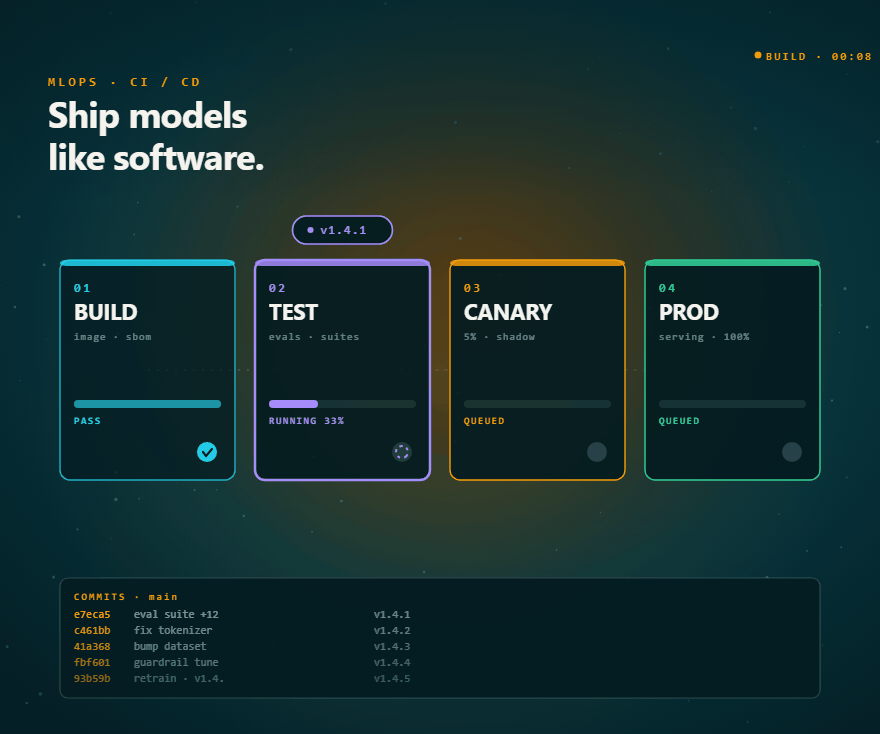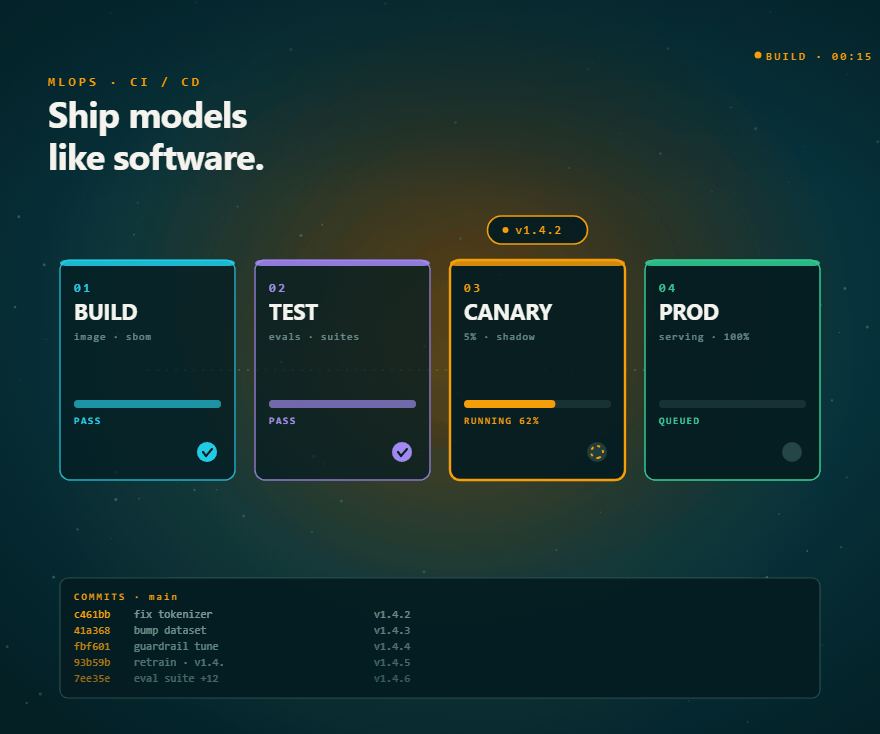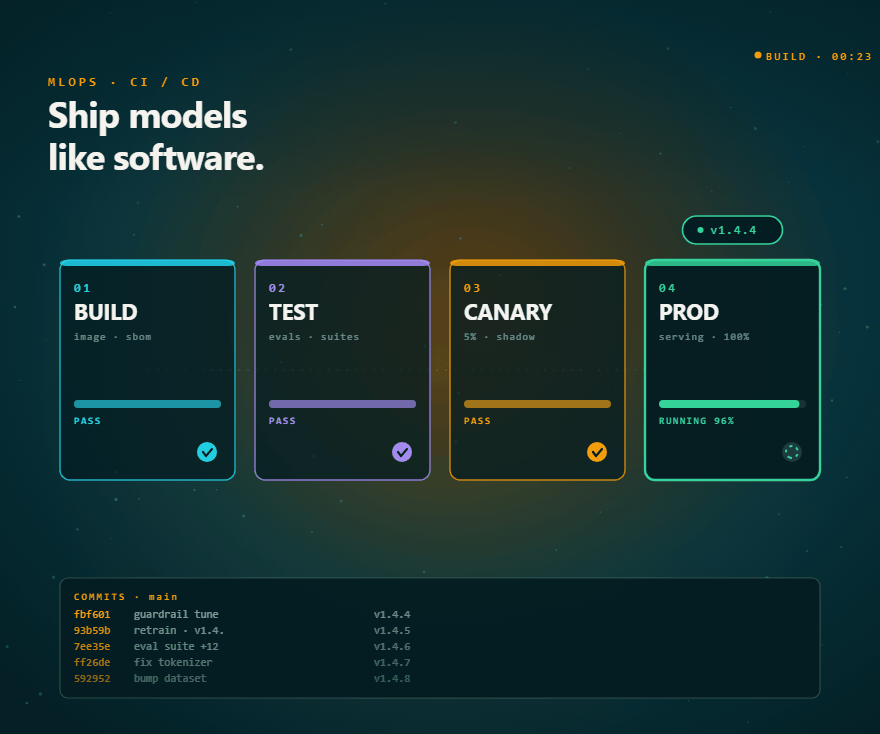
MLOps
From notebook to production.
Training a model is the easy part. Keeping it reliable across retraining cycles, data drift, and regulatory scrutiny is where most ML programmes fall over. We build the lifecycle infrastructure that turns experiments into engineered systems.
- CI/CD pipelines for ML models with automated testing, rollback, and approval gates
- Model registry and versioning with full reproducibility across environments
- Feature stores with online and offline parity
- Drift detection, data quality monitoring, and automated retraining triggers
- A/B testing and shadow deployment infrastructure
- Experiment tracking and lineage from training data to inference endpoint

LLMOps
Because prompts are code, and evaluation isn't optional.
Running LLMs in production is a different discipline from classical ML. Models change weekly, costs spiral without warning, and "it works in testing" means nothing when real users ask real questions. We build the operational layer that keeps LLM applications cheap, fast, evaluated, and safe at scale.
- Prompt versioning, testing, and deployment workflows
- Evaluation harnesses with golden datasets and regression testing
- Token-level cost and latency monitoring across providers and models
- Guardrail testing for safety, bias, hallucination, and policy compliance
- A/B testing across prompts, models, and retrieval strategies
- Feedback collection and continuous improvement loops

Agent Orchestration
Multi-agent systems you can actually operate.
The agent era is real, but most agent systems are held together with tape. We build production-grade agent orchestration — with clear tool boundaries, governed data access, observability across every call, and the ability to debug quickly.
- Multi-agent pipelines with explicit routing, decomposition, and synthesis patterns
- MCP server design and deployment for governed tool access
- Tool registries with permission scoping and audit trails
- Agent observability — traces, spans, token usage, tool calls, and failure modes
- Evaluation frameworks for end-to-end agent workflows
- Guardrails and fallback paths for when agents fail gracefully

Model Governance & Compliance
AI you can defend in an audit.
Regulated industries don't just need models that work — they need models that can be explained, documented, and defended when regulators ask. We build the governance infrastructure that turns AI from a compliance risk into a compliance asset.
- Model cards, datasheets, and full audit trails for every production model
- Fairness, bias, and explainability monitoring with actionable reporting
- Data lineage from training set to inference output
- Access controls, approval workflows, and change management for model deployment
- Regulatory documentation aligned to EU AI Act, RBI guidelines, and industry frameworks
- Incident response playbooks for model failures and bias events