Comprehensive Data Solutions

Real-Time Pipelines & CDC
From source change to downstream decision, in milliseconds.
We build streaming pipelines that capture every insert, update, and delete the moment it happens, so your warehouse, your dashboards, and your agents are never looking at yesterday's truth.
- Cloud-native streaming pipelines on AWS, Azure, or GCP
- Debezium-based CDC across Postgres, MySQL, MongoDB, SQL Server, Oracle
- In-flight validation and schema evolution without downtime
- Dead-letter queue design with automated replay
- Exactly-once delivery guarantees where it matters
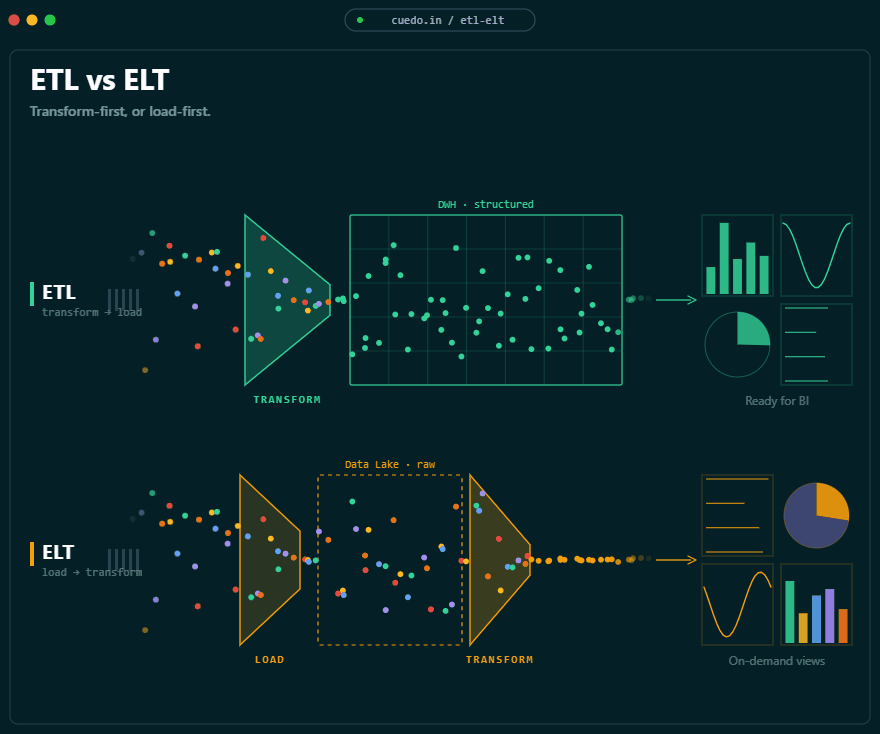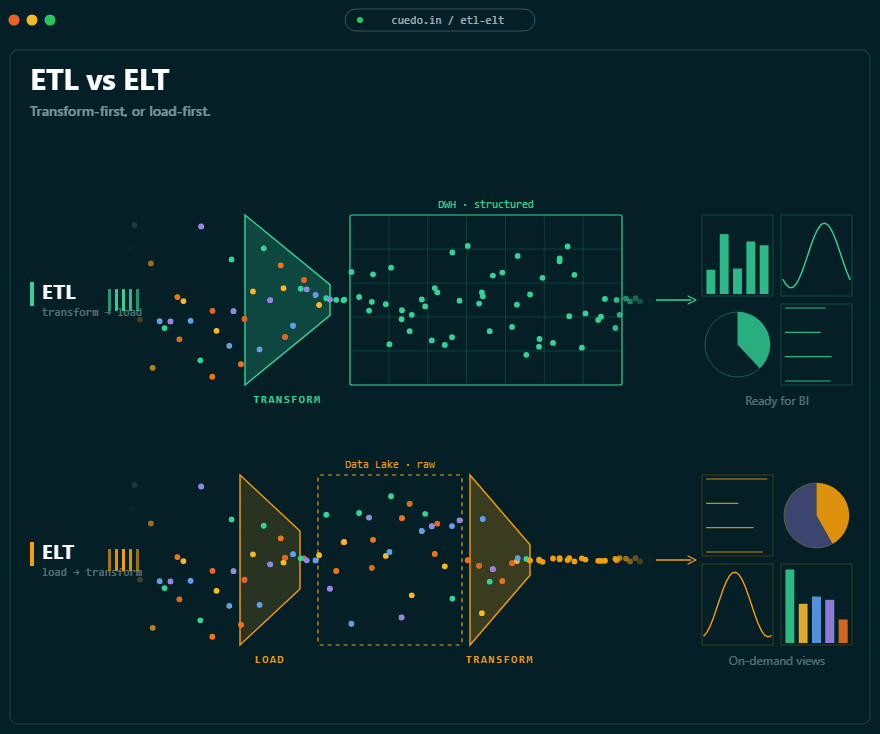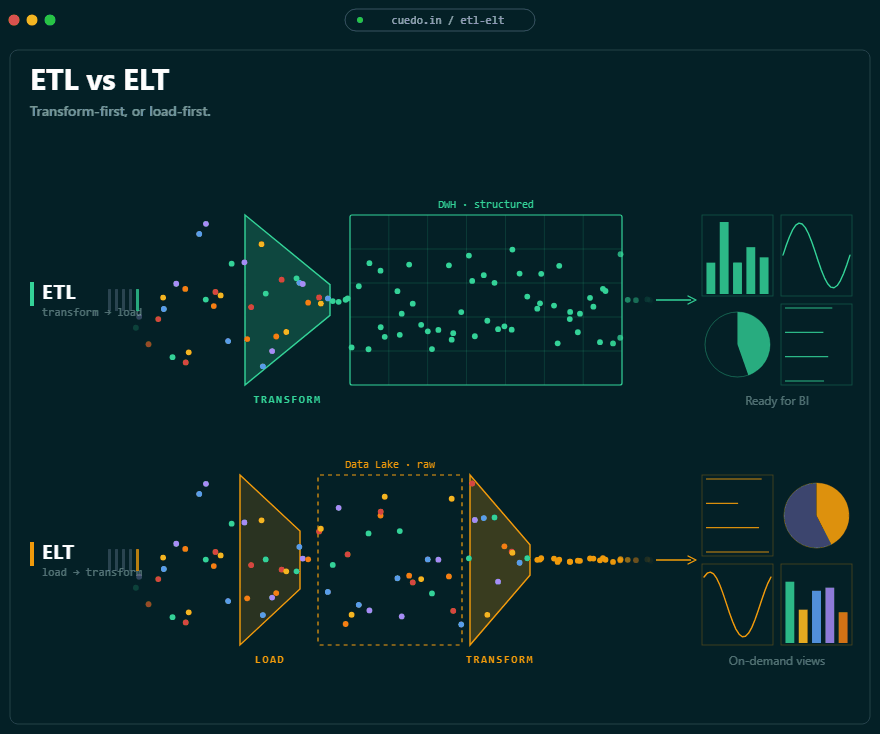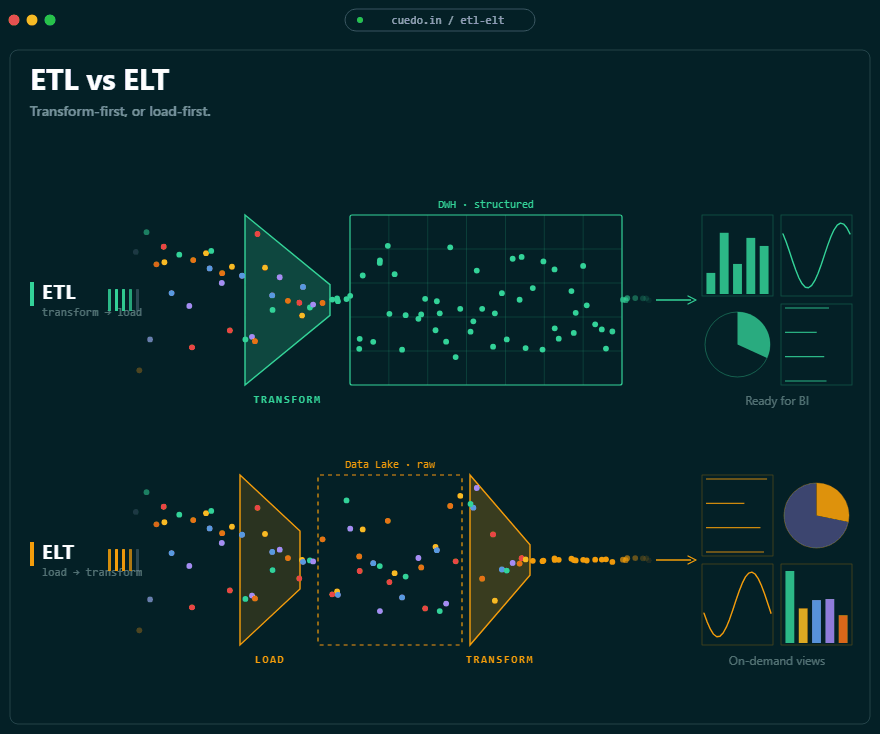
ETL / ELT Development
Raw data is a liability. We turn it into an asset teams trust.
Most pipelines are held together by tribal knowledge and Slack threads. Ours are modular, tested, documented, and incremental by default — so refreshes are cheap, failures are loud, and lineage is never a mystery.
- dbt models with enforced testing and CI/CD
- Spark-based transformations on AWS, Azure, or GCP
- Data quality contracts that fail loudly, not silently
- Orchestration on Airflow, Dagster, or native cloud services
- Auto-generated documentation your analysts will actually read

API & SaaS Ingestion
Your data lives in forty tools. We bring it home—reliably, completely and on time.
Salesforce, HubSpot, Stripe, Zendesk, NetSuite, internal APIs, partner feeds. Every source has its own quirks, rate limits, and failure modes. We've seen them all and designed around them.
- Airbyte deployments and custom Python connectors where off-the-shelf falls short
- Bespoke API integrations with retry, backoff, and idempotency built in
- Incremental extraction logic that handles pagination, cursors, and time windows correctly
- Schema drift detection with automated alerting
- Full audit trails for every row ingested

Data Modelling & Architecture
The shape underneath decides the speed above.
A well-designed model answers questions in milliseconds. A bad one requires a data engineer every time marketing asks about last quarter. We design schemas for how your business ought to think.
- Kimball dimensional modelling with conformed dimensions
- Star and snowflake schemas optimised for your query patterns
- Slowly changing dimensions (Type 1, 2, and hybrid) done right
- One Big Table and wide-table patterns where they outperform joins
- Partitioning, clustering, and materialisation strategies tuned to your workload

Automation & Monitoring
Pipelines that watch themselves and speak to you before your users do.
The worst data incidents are the silent ones. We instrument every pipeline with freshness checks, volume anomaly detection, and SLA tracking, so problems surface on your dashboard, asap.
- SLA-based alerting with noise suppression that actually works
- Freshness, volume, and distribution monitors on every critical table
- Cost observability dashboards (per-pipeline, per-team, per-query)
- Automated retry, backfill, and recovery workflows
- Runbooks your on-call engineer will thank you for

Warehouse & Lakehouse Build-Outs
Greenfield or migration — we deploy storage that scales without surprises.
Whether you're building your first warehouse or moving off one that's buckling under its own cost, we design for the next five years, not the next quarter. Open formats, clear governance, predictable bills.
- Cloud-native warehouse implementations on AWS, Azure, or GCP
- Open lakehouse architectures on Apache Iceberg, Delta Lake, or Apache Hudi
- Multi-cluster and multi-workload optimisation
- Cost governance frameworks with chargeback and showback
- Role-based access control, row-level security, and audit logging
- Cross-cloud migration playbooks (AWS ↔ Azure ↔ GCP)